Traitement sur données chiffrées dans un contexte multi-utilisateurs
Contexte
Nous nous intéressons à un nouveau service que souhaite proposer une entreprise. Ce service est destiné d’une part aux individus qui vont pouvoir comparer leurs données personnelles avec d’autres, et d’autre part à d’autres entreprises, à des associations ou à des laboratoires qui vont pouvoir obtenir des statistiques portant sur les données personnelles d’individus.
L’objectif est de permettre la mise en place d’une telle solution tout en protégeant la vie privée des individus qui vont participer. La solution à mettre en place se basera sur des mécanismes de cryptographie avancée.
De façon plus formelle, le système que nous proposons d’étudier vise à calculer une fonction sur un ensemble de données provenant d’individus. En pratique, une telle fonction pourra être une moyenne, une moyenne pondérée ou une régression linéaire (voir détails plus bas). Chaque donnée proviendra d’un individu . L’objectif global est de protéger ces données vis- a-vis d’un maximum d’acteurs, selon differentes configurations (voir détails plus bas).
Acteurs
Notre syst eme va donc comporter trois types d’acteurs:
- un tiers qui va proposer des études, chacune d’elle portant sur les données d’utilisateurs et permettant finalement d’obtenir un certain résultat, sortie d’une fonction définie par l’étude ;
- des individus qui vont consentir à participer à une étude (un consentement par étude), fournissant pour cela une donnée que nous considérons comme sensible et personnelle, et obtenant au final le résultat final leur permettant de se comparer avec les autres individus ayant participé;
- une société de traitement qui va permettre et effectuer le traitement proposé par le tiers. Cette société sera donc l’intermédiaire entre le tiers et l’ensemble des individus.
Contraintes
Nous allons maintenant nous intéresser aux contraintes que nous souhaitons étudier, en abordant plusieurs aspects.
Fonctionnalités
L’objectif des contraintes suivantes portant sur les échanges est de s’imaginer à la place de la société de traitement qui souhaite mettre en place un service à la fois pour les tiers et pour les individus. Son désir est d’avoir un service irréprochable dans lequel lui peut avoir une charge de calcul lourde, mais pas ses clients (ni les individus, ni les tiers).
Ainsi, d’un point de vue fonctionnalités, nous avons les contraintes suivantes :
- parmi tous les individus possibles, nous ne savons pas à l’avance qui va effectivement participer en envoyant ses données à la société. En effet, un individu peut à tout moment soit décider qu’il ne participera finalement pas, soit avoir un problème avec son matériel l’empêchant de participer ;
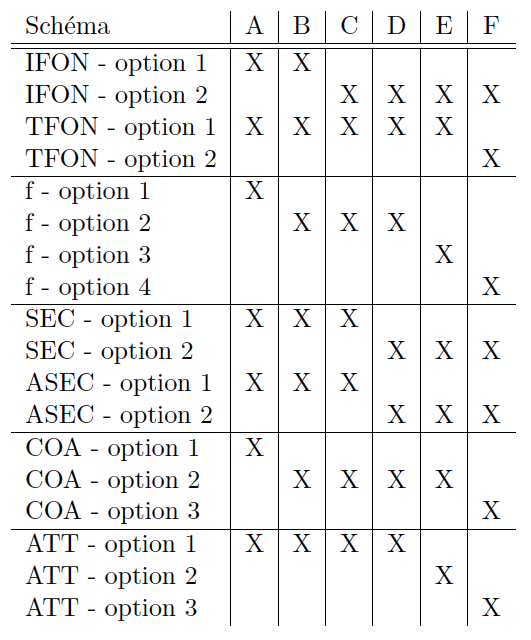
- pour ne surcharger les actions de chaque individu, ce dernier doit avoir un minimum de choses à faire. Nous allons considérer qu’il n’y a systématiquement qu’une seule session possible entre un individu et la société de traitement. Cette session pourra impliquer de multiples échanges entre l’individu et la société de traitement [IFON – option 1] ou ne demander qu’une seule et unique action (et un seul envoi) à effectuer, à savoir protéger et envoyer sa donnée personnelle [IFON – option 2]. Ainsi, en complétant avec la contrainte au-dessus, au moment de son envoi, un individu ne sait pas qui sont les autres individus qui participent ou vont participer ;
- il peut y avoir de multiples échanges entre le tiers et la société de traitement [TFON – option 1] ou le tiers ne doit avoir qu’une seule action à effectuer, à savoir recevoir des données provenant de la société de traitement et faire un calcul cryptographique pour obtenir le résultat final [TFON – option 2].
Détails sur la fonction f
Pour la fonction f, de multiples possibilités peuvent être abordées. Nous allons principalement envisager les quatres suivantes, par ordre de priorité :
1. une moyenne [f – option 1] ;
2. une moyenne pondérée avec des pondérations publiques [f – option 2] ;
3. une régression linéaire [f – option 3] ;
4. une fonctionnalité quelconque [f – option 4].
Sécurité
D’un point de vue sécurité, l’aspect le plus important concerne bien évidemment la sécurité des données provenant des individus.
Nous considérons que l’individu ne consent à fournir ses données que pour une fonctionnalité donnée (e.g., calculer une moyenne, voir au-dessus les détails sur la fonction f), et que toute autre fonctionnalité doit être impossible. Mais comme nous l’avons vu au niveau des contraintes liées aux fonctionnalités, les individus ne peuvent pas savoir quels autres individus vont réellement participer à une étude. Nous allons donc distinguer les 2 cas suivants :
- seule la fonctionnalité f est possible et tout autre fonction sera considérée comme une attaque qu’il faut pouvoir contrer [SEC – option 1];
- seule la fonctionnalité f sur l’ensemble exact des individus participants est possible et tout autre calcul sera considéré comme une attaque qu’il faut pouvoir contrer [SEC – option 2].
De ce point de vue, nous avons les contraintes suivantes :
- un individu ne doit prendre connaissance que de sa valeur personnelle et du résultat (voir SEC options 1 et 2 au-dessus) ;
- le tiers ne doit finalement connaître que le résultat (voir SEC options 1 et 2 au-dessus) ;
- la société de traitement ne doit rien apprendre [ASEC – option 1] ou doit uniquement apprendre le résultat [ASEC – option 2] (voir SEC options 1 et 2 au-dessus).
Nous allons envisager plusieurs options concernant les possibilités de coalitions entre ces différents acteurs.
- Aucune coalition/corruption ne sera possible [COA – option 1].
- Le tiers et la soci et e de traitement peuvent de fa con ind ependante corrompre un nombre limité d’individus [COA – option 2].
- Le tiers et la société de traitement peuvent former une coalition [COA – option 3].
Prise en compte d’attributs
Par défaut ([ATT – option 1]), la seule donnée envoyée par chaque individu sera sa propre valeur personnelle.
Une option ([ATT – option 2]) consiste à associer chaque individus à un ensemble d’attributs, et de calculer les statistiques (la fonction f) par attribut. Pour chaque attribut, un individu ne peut avoir qu’un seule valeur. Dans cette option, l’idée est de calculer les fonctions ci-dessus par valeur d’attributs.
Prenons un exemple en considérant l’attribut `âge’. Celui peut par exemple prendre les 7 valeurs suivantes : [20,30[, [30,40[, [40,50[, [50,60[, [60,70[, 70+. Dans le cas par exemple de la moyenne, nous souhaitons donc obtenir la moyenne pour les personnes ayant entre 20 et 30 ans, la moyenne pour les personnes ayant entre 30 et 40 ans, etc.
Comment pouvons-nous réaliser cela sans que l’individu ne révèle la valeur de ses attributs ?
Dans une dernière variante, nécessaire dans le contexte du RGPD (problématique du k-anonymat), la société de traitement et le tiers ne doivent être capables de calculer les moyennes que si le nombre de participants est supérieur à une borne k fixée et connue [ATT – option 3].
Tableau récapitulatif et priorisation
Voici un tableau récapitulatif de toutes les options possible décrites ci-dessus. Les lignes sont données par ordre de priorité. Il est donc conseillé (mais tout ordre différent reste pertinent) de démarrer par tenter de trouver un schéma satisfaisant les contraintes de la première colonne (schéma A), puis de la seconde (schéma B), etc.